
티스토리 뷰
레지스터 플로우
이전 글에서 CPU의 내부 구조에 대해서 알아보았고, 이번에는 레지스터가 동작하는 방식을 알아보려한다.
레지스터에 데이터가 인출되는 사이클과 실행되는 사이클을 간략하게 하면 다음과 같다.
- 프로그램 실행 버튼 클릭
- 운영체제 혹은 실행 환경에서 해당 프로그램의 실행 정보를 메모리에 적재
- 프로그램 명령어들의 메모리 위치를 포함하고 초기화 및 실행에 필요한 데이터 포함
- 운영체제 혹은 실행 환경에서 프로그램의 시작 지점에 해당하는 주소를 PC에 생성 및 설정
- PC에서 명령어를 인출하여 MBR로 경유
- MBR에서 IR에 명령어 저장
- 실행 사이클에서 제어 유니트로 보내져 해독
- MAR은 CPU 내부 주소 버스와 시스템 주소 버스 사이에서 버퍼 역할
- MBR은 데이터에 대하여 내부 데이터 버스와 시스템 데이터 버스 사이 버퍼 역할
- 메모리에서 데이터를 인출하여 MBR로 경유
- MBR에서 AC로 데이터 적제
- 적제 된 데이터에 산술/논리 연산이 필요할 경우 AC 내용이 ALU로 전달
- ALU 연산 결과를 AC에 다시 저장
인출 사이클(fetch cycle)
CPU가 메모리의 지정된 위치로부터 명령어를 읽어오는 과정을 인출 사이클이라고 한다. 이를 마이크로-연산으로 표현하면 다음과 같다.

$t0$ : MAR ← PC
$t1$ : MBR ← MAR, PC ← PC + 1
$t2$ : IR ← MBR
※ $t$는 CPU의 클록 주기 를 의미하고 위 과정에서 명령어 인출에는 총 3 클록의 시간이 사용되었다.
위 과정에서 $t0$부터 PC 내용을 CPU 내부 버스로 MAR로 보낸다. 그러면 시스템 주소 버스와 직접 연결되는 MAR을 통해 주소가 메모리로 전송된다. MAR을 통하는 이유는 내부 주소 버스와 시스템 주소 버스를 연결하기 위해서 이다.
$t1$에서 전송된 주소 위치에서 명령어를 읽어 데이터 버스를 통해 MBR로 적제된다. 그와 동시에 PC 내용이 1 증가하여 다음 명령어 주소를 가리킨다. (만약 CPU의 단어 길이가 8비트이고 명령어의 크기가 16비트라면 PC에 2를 더하여 다음 명령어 위치로 이동한다.)
마지막으로 $t2$에서 MBR에 저장되어 있는 명령어 코드가 IR로 이동한다.
실행 사이클 (execute cycle)
CPU가 명령어를 해독하고, 그 결과에 따라 필요한 연산을 수행하는 과정을 실행 사이클이라 한다.
CPU가 수행하는 연산들은 매우 다양하지만 크게 네 분류로 나눈다.
| 명칭 | 설명 | 대표 연산 |
| 데이터 이동 | CPU와 메모리 간 혹은 CPU와 I/O 장치 간 데이터 이동 | LOAD addr |
| 데이터 처리 | 데이터에 대해 산술 혹은 논리 연산 수행 | ADD addr |
| 데이터 저장 | 연산 결과 데이터 혹은 입력장치에서 온 데이터를 기억장치에 저장 | STA addr |
| 프로그램 제어 | 프로그램에 실행 순서 결정 | JUMP addr |
LOAD addr (데이터 이동)
$t0$ : MAR ← IR(addr)
$t1$ : MBR ← MAR
$t2$ : AC ← MBR
메모리에 저장된 데이터를 CPU 내부 레지스터 AC로 이동하는 명령어이다.
ADD addr (데이터 처리)
$t0$ : MAR ← IR(addr)
$t1$ : MBR ← AC
$t2$ : AC ← AC + MBR (ALU)
메모리에 저장된 데이터를 AC 레지스터에 내용과 연산하고, 그 결과를 다시 AC 레지스터에 저장하는 명령어이다.

STA addr (데이터 저장)
$t0$ : MAR ← IR(addr)
$t1$ : MBR ← MAR
$t2$ : MAR ← MBR
AC 레지스터의 내용을 메모리에 저장하는 명령어이다.
JUMP addr (프로그램 제어)
$t0$ : PC ← IR(addr)
순서와 상관없이 특정 명령어를 수행해야 하는 경우, 명령어 실행 순서를 바꾸는 명령어이다.
인터럽트 사이클
대부분 컴퓨터는 CPU에게 순차적 명령어 실행을 중단하고 다른 프로그램을 처리하도록 요구하고 이를 인터럽트라고 한다.
이러한 과정을 수행하기 위해 인터럽트 서비스 루틴(interrupt service routine: ISR)이라는 프로그램을 사용하기도 하며, 인터럽트가 끝나면 복귀하여 원래 작업을 진행한다.
CPU는 인터럽트 요구가 요청되면 어떤 장치에서 요청하는지 확인하여 해당 인터럽트 서비스 루틴을 수행하고, 인터럽트가 종료되면 중단되었던 원래 프로그램의 수행을 계속한다. 그를 위해 CPU는 각 명령어 실행 사이클이 종료되고 다음 명령어 인출 사이클을 시작하기 전, 인터럽트 요구 신호가 요청되어 대기하고 있는지 검사한다.
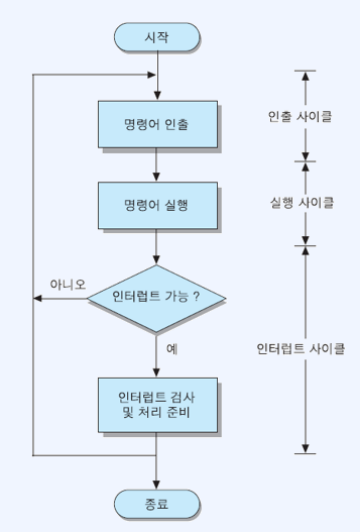
인터럽트 사이클 (interrupt cycle)
- 인터럽트 요구 신호 검사
- 원래 실행되어야 했던 다음 명령어 주소를 가리키는 PC 내용을 스택(stack)에 저장
- 인터럽트 처리 후 복귀할 주소 저장
- 인터럽트 서비스 루틴 호출을 위하여, 루틴 시작 주소를 PC에 적재
- 시작 주소는 인터럽트를 요구한 장치나 미리 정해진 값으로 결정
위 그림에서 인터럽트를 검사하는 단계에서 인터럽트가 발생다면, 바로 위에 나열한 과정이 진행되고 이를 인터럽트 사이클이라고 명칭 한다.
인터럽트 상태
인터럽트를 요청한다고 반드시 이루어지는 것은 아니다.
CPU가 현재 실행하는 프로세스가 더욱 중요하다면 인터럽트를 무시할 수 있고, 인터럽트를 받을 수 있는 상태가 되어야만 인터럽트가 발생한다.
이러한 상태를 '인터럽트 가능 (interrupt enabled)', '인터럽트 불가능 (interrupt disabled)' 상태로 나누어 관리한다. 이 상태는 CPU가 해당 명령어를 수행하며 변경할 수 있다.
$t0$ : MBR ← PC
$t1$ : MAR ← SP, PC ← ISR 시작 주소
$t2$ : MAR ← MBR, SP ← SP - 1
- PC 내용을 MBR로 전송 (복구 대비)
- SP 내용이 MAR을 통해 주소 버스로 이동
- PC에 인터럽트 서비스 루틴 시작 주소 적재
- MBR에 저장된 원래 PC 내용을 스택에 저장
- 동시에 SP 내용을 1 감소하여 TOS 주소 수정
위 과정은 인터럽터가 수행되는 마이크로-연산 표현이다. 여기서 SP는 CPU 내부의 특수 목적 레지스터 중 하나인 스택 포인터(stack pointer)이다. 스택 포인터는 항상 스택의 최상위(top of stack: TOS)의 주소를 가리킨다.
다중 인터럽트 (Multiple interrupt)
인터럽트 서비스 루틴의 명령어가 실행되는 동안에도 다른 인터럽트 요구가 발생할 수 있다. 이를 다중 인터럽트라고 하는데, 이를 처리하는 방법은 두 가지가 있다.
인터럽트 불가능 상태로 전환
첫 번째 방법은 하나의 인터럽트가 진행 중에는 다른 인터럽트가 오지 못하도록 인트럽트 불가능 상태로 전환하는 것이다.
이렇게 되면, 그 루틴을 처리하는 동안 다른 인터럽트는 대기 상태로 남고, CPU가 다시 인터럽트 가능 상태로 바꾸어야 인식되어 다음 인터럽트가 실행된다.
인터럽트 우선순위 설정
두 번째 방법은 인터럽트 요구들 간에 우선순위를 정하는 것이다. 이를 통해 현재 인터럽트보다 높은 순위의 인터럽트가 발생하면 기존 인터럽트를 중단하고, 해당 인터럽트를 먼저 처리하도록 스케줄링한다.
이 경우 PC 내용을 저장하고 갱신하는 절차가 자주 발생할 수 있다. 하여 복구를 위해 사용되는 스택이 PC의 원래 주인과 인터럽트의 복귀 주소도 저장하게 된다.
간접 사이클
데이터에 대한 연산을 수행하는 경우에, 명령어에는 그 데이터를 읽어오기 위한 기억장치 주소가 포함되어 있다.
이게 되게 복잡하게 설명되어있기도 한데, 오퍼랜드 주소가 직접적으로 데이터를 포함하는 위치가 아니라, 데이터가 있는 주소를 가리키는 레지스터의 값을 사용하여 메모리에 접근하는 방식이다.
즉, 메모리 주소를 직접적으로 지정하는 대신, 해당 주소를 가리키는 레지스터의 값을 사용하여 데이터에 접근하는 것으로 데이터가 어디있는지 알려주는 주소로 먼저 찾아가고 확인한 진짜 데이터가 존재하는 주소를 찾아가는 것이다.
이것은 데이터가 포인터(pointer)나 인덱스(index) 등의 형태로 표현되어 있을 때 매우 유용하다. 예를 들어, 배열의 요소에 접근할 때 배열의 시작 주소를 가리키는 레지스터에 있는 값을 사용하여 해당 배열 요소에 접근할 수 있다.
이러한 간접 주소 지정은 프로그램의 유연성을 높이고 코드의 재사용성을 증가시키는 데 도움이 된다. 그러나 간접 주소 지정을 사용할 때는 추가적인 간접 사이클이 발생하여 명령어 실행 속도가 느려질 수 있다는 점을 고려해야 한다.
'Computer > Computer Science' 카테고리의 다른 글
| [컴퓨터구조] CPU의 구조와 기능 - 기본 구조 (0) | 2024.03.13 |
|---|---|
| [컴퓨터구조론] 메모리 계층구조 시스템 (Hierachy Memory System) (0) | 2023.12.04 |
| [컴퓨터구조] 시스템의 구성 (CPU와 Memory, System Bus) (0) | 2023.10.01 |
| [컴퓨터구조] 정보의 표현과 저장 (0) | 2023.08.26 |
| [컴퓨터구조] 컴퓨터시스템 개요 (0) | 2023.08.26 |
- Total
- Today
- Yesterday
- 운영체제
- 레지스터
- 백준
- 클래스
- const
- 메모리
- 게임수학
- 크기
- 포인터
- 프로세스
- 구조
- 컴파일
- 입출력
- 함수
- static_cast
- 멀티스레드
- CPU
- 초기화
- 할당
- malloc
- dynamic_cast
- thread
- 상속
- 수학
- 알고리즘
- 스레드
- New
- c++
- 명령어
- 인터럽트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |